slurper 可以将任何格式的数据导入HDFS, 这里有 这里鄙视下百度,居然搜索不到!
第一步,下载安装
git clone git@github.com:alexholmes/hdfs-file-slurper.git
cd hdfs-file-slurper
mvn package
将target下的hdfs-slurper-0.1.8-package.tar.gz 解压到 /usr/local目录下(笔者的工作环境是ubuntu)
配置sluper,配置文件在conf目录下
slurper.conf 配置
#被传输数据的名称DATASOURCE_NAME = test#数据源目录,输入到这的任何文件都会自动复制到目标目录中(中间会被复制到临时目录中)SRC_DIR = file:/data/hadoop/tmp/slurper/in#工作目录,来自数据源的文件在复制到目标目录前被移入这个目录WORK_DIR = file:/data/hadoop/tmp/slurper/work#在复制完成后,文件从工作目录移入最终目录,另外REMOVE_AFTER_COPY可以设置被用于设置删除源文件,这时不能设置COMPLETE_DIRCOMPLETE_DIR = file:/data/hadoop/tmp/slurper/completeREMOVE_AFTER_COPY = false#在复制文件中遇到的任何错误都会被移入这个目录ERROR_DIR = file:/data/hadoop/tmp/slurper/error#临时目录,文件第一次被复制到目标文件系统上的临时目录。然后文件复制完成后,通过slurper将这个文件移入目标文件DEST_STAGING_DIR = hdfs:/tmp/slurper/stage#源文件最终存放目录DEST_DIR = hdfs:/tmp/slurper/dest
file://URI 表示本地文件系统,hdfs://URI表示HDFS中的文件路径
slurper-env.sh 中要配置hadoop bin文件目录
运行:
1. 先创建 源文件目录 /data/hadoop/tmp/slurper/in
2.
bin/slurper.sh --config-file conf/slurper.conf
3.将测试文件复制 到源文件目录,然后就可以看到日志,并且在hdfs上查看文件了
动态设置目标路径:
在slurper bin 目录下有一脚本 sample-python.py
#!/usr/bin/pythonimport sys, os, re# read the local file from standard inputinput_file=sys.stdin.readline()# extract the filename from the filefilename = os.path.basename(input_file)# extract the date from the filenamematch=re.search(r'([0-9]{4})([0-9]{2})([0-9]{2})', filename)year=match.group(1)mon=match.group(2)day=match.group(3)# construct our destination HDFS filehdfs_dest="hdfs:/data/%s/%s/%s/%s" % (year, mon, day, filename)# write it to standard outputprint hdfs_dest, 修改配置文件:
#DEST_DIR = hdfs:/tmp/slurper/destSCRIPT = /usr/local/hdfs-slurper-0.1.8/bin/sample-python.py
再次运行 slurper,然后将文件复制到源文件目录,如果文件 格式不符合正则表达式匹配结果,会报错
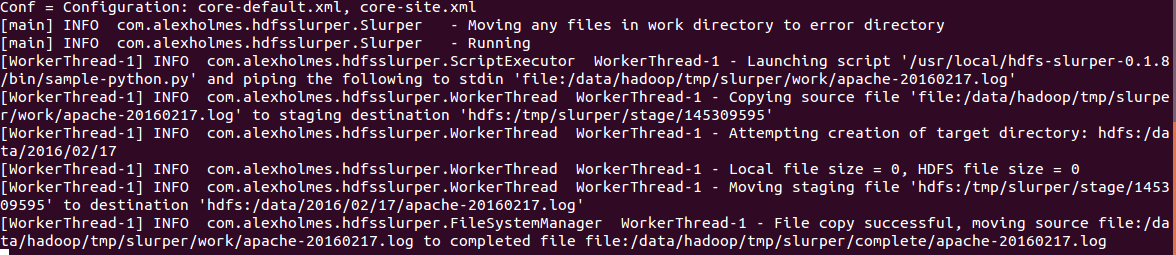

生产环境中,可以使用bin/slurper-inittab.sh 脚本连续操作
此外,sluerper可以将hdfs中的数据导入本地系统!